Bird's eye view
A Lustre file system consists of a number of machines connected together and configured to service filesystem requests. The primary purpose of a file system is to allow a user to read, write, lock persistent data. Lustre file system provides this functionality and is designed to scale performance and size as controlled, routine fashion.
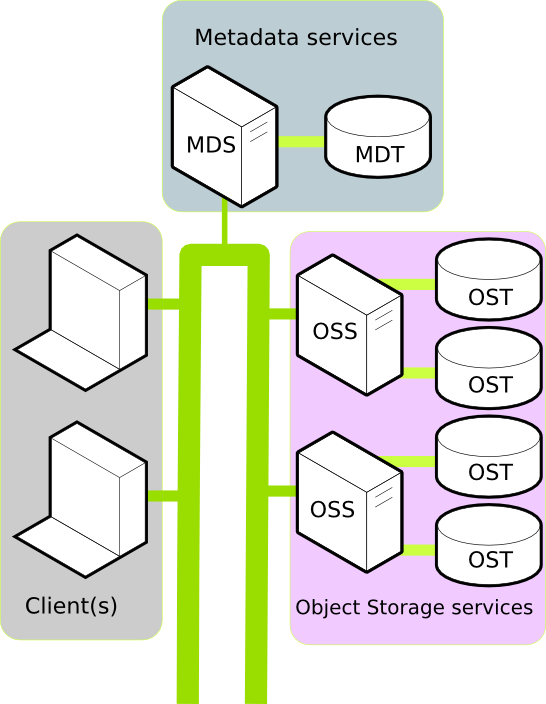
In a production environment, A Lustre filesystem typically consists of a number of physical machines. Each machine performs a well defined role and together these roles go to make up the filesystem. To understand why Lustre scales well, and to consider if Lustre is suitable in your use case, it is important to understand the machine roles within Lustre. A typical Luster installation consists of:
- One or more Clients.
- A Metadata service.
- One or more Object Storage services.
Client
A Client in the Lustre filesystem is a machine that requires data. This could be a computation, visualisation, or desktop node. Once mounted, a Client experiences the Lustre filesystem as if the filesystem were a local or NFS mount.
Further reading: LUSTRE MANUAL LINK
Metadata services
In the Lustre filesystem metadata requests are serviced by two components: the Metadata Server (MDS) an Metadata Target (MDT). Together, the MDS and MDT service requests like: Where is the file XYZ? I'm going to write to file ABC so prohibit anyone else from using it.
All a Client needs to mount a Lustre filesystem is the location of the MDS. Currently, each Lustre filesystem has only one active MDS. The MDS persists the filesystem metadata in the MDT.
Further reading: LUSTRE MANUAL LINK
Object Storage services
Data in the Lustre filesystem is stored and retrieved by two components: the Object Storage Server (OSS) and the Object Storage Target (OST). Together, the OSS and OST provide the data to the Client.
A Lustre filesystem can have one or more OSS. An OSS typically has between two and eight OSTs attached. To increase the storage of the Lustre filesystem, additional OSTs can be attached. To increase the bandwidth of the Lustre filesystem, additional OSS can be attached. Provided the connection to the Client is not saturated.
Further reading: LUSTRE MANUAL LINK
Additional Services
Lustre includes additional services including LNET. LNET is designed to simplify configuration of a Lustre filesystem over complex network topologies.
Further reading: LUSTRE MANUAL LINK
Practical considerations.
Lustre currently has two actively developed and maintained branches. These the are 1.8.x and 2.1 releases. Lustre 2.1 has is not yet ready for production, but it will introduct SMP scaling enhancements to address the issues currently limiting Lustre’s use of more sockets, cores and threads. The Lustre 2.1 release is scheduled to be released at the end of Q2, 2011.
The Metadata Server (MDS) is crucial to overall performance of the Lustre filesystem. Increasing memory on the MDS will increase the cache available and increase performance. It is common to see production MDS machines boast 24GB or 48GB per core.
If your environment is biased toward heavy write, or fast write operations, 16GB is recommenced per Object Storage Server (OSS). If reading is of primary concern, increasing OSS memroy to 48GB will enable significant read caching and greatly increase performance.
For the OSS servers, prior to Lustre 1.8 which introduces OSS read caching, 16 GB or 8GB per core was usually more than sufficient for an OSS server. So, if your environment is primarily a write heavy environment, or if all you care about is the write speed, then 16 GB of memory per OSS server should still be fine. On the other hand, if you think your environment will be able to make use of the OSS read caching, then bumping the OSS server memory up to 48 GB can greatly improve your read performance.
For the MDS servers you would like to have as much memory as you can afford so that you can cache as much as possible in the MDS server. But, the cost to jump to higher GB DIMMs can be prohibitive. We routinely use 48 GB, or 24GB per core for MDS servers and this combination works very well. If you can afford higher amounts of memory then that should be even better.
Further reading
A detailed discussion of Lustre design considerations can be found in the whitepaper LUSTRE WHITEPAPER DOWNLOAD
http://wiki.whamcloud.com/download/attachments/425994/Lustre+OSS+and+MDS+server+node+Requirements+white+paper.docx![]()
Overview
Content Tools