Overview
The intent behind these pages is to provide information on the concepts and technologies behind running Cloud Edition for Lustre on Amazon Web Services. It is not intended to be a replacement for experience or training on general cloud computing concepts.
Amazon Cloud Concepts
In this section, a quick overview of AWS concepts will be presented in order to form a basis for discussing how Lustre runs in AWS.
Instances
AWS provides rentable computing capacity via its Elastic Compute Cloud (EC2) service. EC2 provides Xen-based virtual machines of varying capabilities and capacities at different price points. These virtual machine instances work much like VMs in any other environment. They can be stopped, restarted, and rebooted. When they are terminated, they are permanently stopped and their resources are returned to the resource allocation pool.
Instance Types
As AWS is in a near-continuous state of upgrades, the current set of instance types in EC2 changes fairly often. The EC2 Instance Types list should be consulted for up-to-date information. As of May 2015, the following instance types are recommended for running Lustre:
- OSS: c4.8xlarge
- MDS: c4.8xlarge
- MGS: m3.xlarge
These recommendations should serve as a useful starting point as guidance for potential users who may not be overly familiar with Lustre or EC2. As with any Lustre deployment, the primary consideration is networking performance (c3/c4 instance types have support for Enhanced Networking), followed closely by storage performance and server specs (RAM/CPU). As the specifications improve, the instance cost per hour increases. As with any solution design, finding the best balance between cost and performance requires careful understanding of the solution requirements.
Storage
Instance Store
EC2 instances have access to two different types of block storage. The basic storage option is allocated with each instance and is called Instance Store. These volumes are immediately available on boot as regular linux block devices, and are backed by SSDs on high performance instance types. Instance Store provides high bandwidth and low latency, but does not provide any High Availability (HA) guarantees. If the instance becomes unavailable or is terminated, its storage also goes away. As such, Instance Store is not suitable for most Lustre deployments.
Elastic Block Storage
The other block storage option available to EC2 instances is called Amazon Elastic Block Storage (EBS). EBS volumes exist independently of specific instances, and can persist indefinitely. It is possible to attach an EBS volume to an instance, store data on the volume, terminate the instance, and then attach the volume to a new instance. EBS volumes may only be attached to one instance at a time. When an EBS volume is attached to a Linux instance, it appears as a normal block device, typically starting at /dev/sdf and increasing from there.
Amazon doesn't provide details about the implementation details behind EBS, but it seems to involve striping data across "real" block storage (SSD or magnetic) and S3. The overall result is that a given EBS volume is likely to be more reliable than an equivalently-sized physical drive, but Amazon doesn't publish MTBF statistics so we cannot confirm this. Failures do still happen, so any Highly Available solution needs to plan for them.
As of May 2015, the gp2/io1 volume types can be anywhere from 1GiB to 16TiB in size. There is not currently a published maximum limit to the number of attached volumes per instance.
Volume Types
There are three different types of EBS volumes that can be created. For Lustre, the general purpose type (gp2) is the most cost effective and practical type. The AWS documentation on EBS Volume Types will provide the most information, but the following list is a quick reference:
- standard: Magnetic (i.e. "spinning rust"). This type is largely deprecated, at least for high performance workloads. Cheapest, but slowest.
- gp2: General Purpose SSD. This type has a baseline performance guarantee of 3 IOPS/GiB (i.e. for every GiB provisioned, you get a guaranteed 3 IOPS).
- io1: Provisioned IOPS. Higher bandwidth, lower latency. Guaranteed IOPS performance. Most expensive option.
Simple Storage Service
Amazon Simple Storage Service (S3) provides secure, durable, highly-scalable object storage. The basic idea is that it is a giant key/value store. Blobs of bits are stored as values which can be retrieved by the user-supplied keys. There is some metadata "magic" available to impose directory-like hierarchies, if desired. The basic unit of S3 organization is the bucket. A bucket has a name which must be unique within an account, and in turn provides access to the objects stored within the bucket. ACLs may be set on the bucket to ensure appropriate access to the bucket contents.
Cloud Edition itself does not currently use S3 for storage, but it's helpful to know something about it when discussing user requirements. As of version 1.0.1, CE does support automatic import of bucket contents after filesystem creation. This feature can be useful in the case where a user wants to work with large public data sets shared via S3.
Networking
There are two different networking options available for EC2 instances. The original networking option is now called EC2 Classic (your instances are launched in a flat network shared with other customers), and is being deprecated. The preferred networking option for instances is Amazon Virtual Private Cloud (VPC), and this is also the option recommend for CE.
The VPC option allows instances to be launched in logically isolated sections of AWS that are independent of other users. Each Amazon account has its own VPC created by default, and users may choose to create additional VPCs to suit individual requirements.
As was mentioned in an earlier section, each instance type has particular specifications for compute capacity (vCPU count), system RAM, and networking performance. For production Lustre deployments, it is recommended not to use instance types without the Enhanced Networking capability.
Deployment Considerations
Aside from choosing the correct instance type, another important step in developing a solution is to understand the required network topology. By default, instances deployed in a VPC have private IP addresses and no network access outside of the VPC. This implies a lack of access to AWS service endpoints – a detail that can cause problems for some customer deployments. In order for CE to configure a Lustre cluster, the software must have access to AWS endpoints (ec2, s3, etc.). Access from instances from the VPC may be facilitated by use of NAT instances or proxy servers. Another option is to assign a public IP address to each instance, but this solution is likely cost prohibitive and not advisable for security reasons.
Placement Groups
In order to realize guaranteed 10Gbps bandwidth between instances, the user must define a Placement Group (PG) and launch instances into that PG. The downside to use of PGs is that EC2 may have a difficult time co-locating enough instances to fulfill the request, in which case a capacity error will be returned.
Software Distribution
Cloud Edition is made available to the public via Amazon Machine Images (AMIs). An AMI is a bootable disk image with some metadata around it. For each CE release, we create a fresh CentOS image from scratch and then add the required Lustre components to it. Each AMI has a unique ID, and the ID is how users specify which AMI(s) should be used for the instances in their cluster.
You may be wondering if sharing a disk image to be used by the general public is a good idea - What happens if they install new software? The answer is that each instance gets a new copy of the AMI's contents. This is done behind the scenes via EBS snapshots and other "magic". The end result is that each instance has its own writable copy of the AMI which is completely isolated from the original, and when the instances are terminated, the copies are deleted.
AWS Marketplace
AWS Marketplace provides a medium by which software vendors may make their products available for use by the public on Amazon Web Services. AMIs shared on Marketplace may have a cost associated with them, such that the user pays for the use of the AMI in addition to the underlying AWS services used.
See the following pages for current details on our AWS Marketplace offerings:
- Cloud Edition for Lustre software on AWS Marketplace
- Cloud Edition for Lustre Software - Whamcloud Wiki
- Cloud Edition for Lustre on AWS Setup
- Product Page for Cloud Edition for Lustre* software on Intel.com
GovCloud
As of mid 2015, Cloud Edition is also available to users with access to the GovCloud region. GovCloud is a secure, isolated environment suitable for workloads requiring ITAR and other regulations mandated by the US Government for sensitive information.
There is no Marketplace distribution option available within GovCloud, and as a result support arrangements should be handled directly with Whamcloud. Please contact our sales or support team for more details.
Cloud Edition for Lustre Software
This section will provide an overview of the product itself. When appropriate, links to wiki entries with additional details will be provided.
Product Goals
- Enable cloud-based compute workloads to use high performance Lustre storage
- Provide a consistent, reliable way of creating, managing, and monitoring Lustre in cloud environments
- Reduce the overall complexity of provisioning and managing a Lustre storage soluiton
Solution Overview
Cloud Edition allows a customer to fill out a form, click a few buttons, and in a few minutes have a Lustre filesystem ready and waiting to provide high performance storage for their cloud-based compute cluster.
The basic process is as follows (see Cloud Edition for Lustre on Amazon Web Services for more details):
- Subscribe to the product on AWS Marketplace – this is how the product is activated in your AWS account
- Select a CloudFormation template suitable for your workload and tailor its parameters as needed (number of servers, volume of storage, ratio of volumes to servers, etc); then launch the template
- After CloudFormation has completed creating the filesystem, you can access a web-based console suitable for monitoring the health and performance of the filesystem – this console also conveniently displays a client mount command that you can use to mount the filesystem from compute clients
Solution Details
Major Components
Cloud Edition for Lustre Software provides a High Availability (HA) Lustre filesystem in an AWS Virtual Private Cloud (VPC).
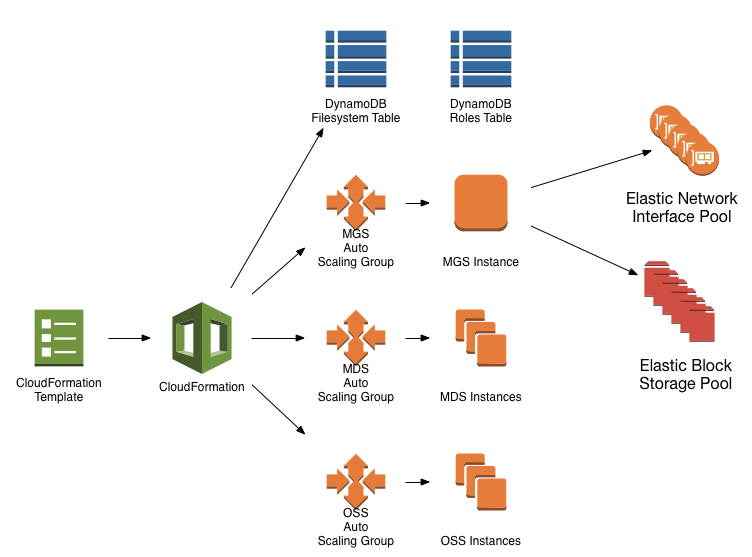
CloudFormation
The first step in creating a Cloud Edition filesystem is to provide a template to CloudFormation (CF). A CF template is essentially a "cluster in a box", in that it specifies all of the details necessary to construct a working cluster of machines in AWS. In addition to virtual machines, CF drives AWS APIs to create network subnets, firewall entries, service ACLs, load balancers, databases, message queues, etc. It's not an exaggeration to say that AWS CF enables software-defined datacenters.
Cloud Edition uses a number of AWS features, but the primary components to know about are: Auto Scaling Groups, DynamoDB tables for service discovery, and ENI/EBS pools.
Auto Scaling Groups
Cloud Edition uses Auto Scaling Groups (ASGs) to maintain the number of Lustre server instances specified by the user as template parameters. When an instance is terminated (due to kernel panic, AWS host migration, or other mishap), the Auto Scaler starts a new instance to restore the correct number of instances. When this facility is coupled with the post-boot configuration and EBS/ENI migration provided by the Lustre initiator script, a High Availability solution for Lustre servers is achieved.
DynamoDB Tables
Cloud Edition utilizes a pair of DynamoDB tables for service discovery and resource registration. When an instance is started by an ASG, the instance "knows" its basic role – i.e. that it is destined to be an OSS, an MDS, or the MGS. Beyond that, it needs to consult with the DynamoDB tables to claim its specific role in the filesystem (e.g. mds01, oss03, etc.) and learn which resources it should use to fulfill that role.
Resource Pools
Each ASG instance must claim a filesystem role (e.g. mgs, mds01, oss04) on startup. Each role is associated with a single Elastic Network Interface (ENI), and each ENI is associated with a set of EBS volumes for that role. Lustre requires stable network identifiers (for this product, TCP NIDs are derived from the Lustre ENI's IP address), hence the instance-independent ENIs. A given NID is associated with some number of Lustre targets (OSTs, MDTs, and MGT). The ENIs and EBS volumes for these roles are all created at once during the CloudFormation creation process, and exist in an unclaimed state until associated with a role. These resource pools are created by a process running on the MGS instance, which is an implementation detail that is not relevant except for troubleshooting.
Instance Initialization
Cloud Edition filesystem servers are started and monitored by ASGs. When an instance is started by an ASG, it runs through a standard Linux boot process (grub -> kernel -> init). Once the instance is running, it starts the cfn-init script, which in turn executes `loci init`. At this point, the following process occurs:
- The instance role type (MGS, MDS, OSS) is determined by checking the instance metadata set by the ASG
- The instance attempts to claim a role for its type
- If the instance is the first claimant for a role:
- the role type index is incremented
- the resources are attached
- resource initialization occurs (mkfs.lustre, etc.)
- targets are mounted and Lustre service commences
- If the instance is not the first claimant for a role:
- it first verifies that the old claimant is not running
- the role resources are attached
- targets are mounted and Lustre service commences
- If the instance is the first claimant for a role:
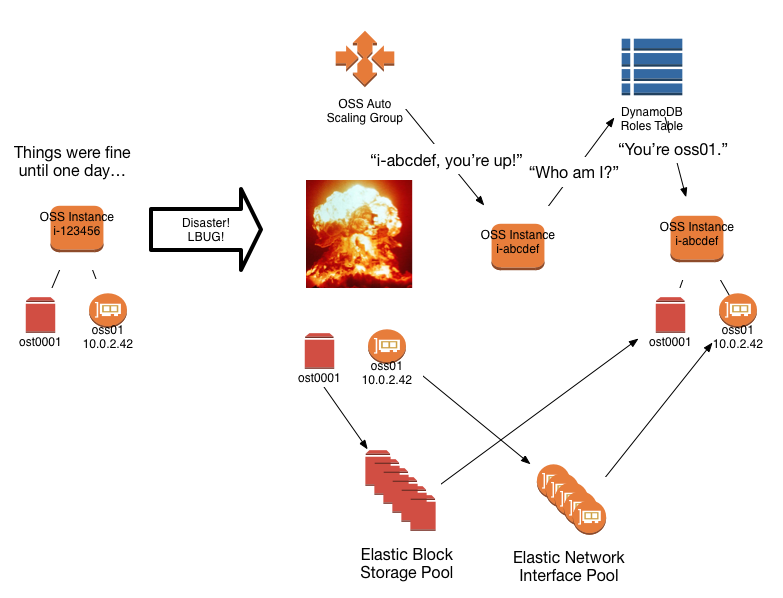
HA and Failover
In a traditional "physical" Lustre deployment (on premise in a private datacenter), HA is achieved through the use of shared storage devices and cluster coordination software (e.g. Pacemaker). A given Lustre server has a peer or peers which share access to a set of block devices, but only one server at a time may mount a given block device. When the primary server for a set of targets becomes unavailable, the cluster coordination software causes those targets to be made available on one of the failover peers, and clients eventually figure out that they have to use the failover peer's NID for those targets.
In cloud deployments, it's much simpler to replace a failed or failing instance with a new one. Lustre doesn't handle server address changes, so each server role's IP address is assigned to an independent network interface (ENI). An ENI can only be attached to a single instance at once. Likewise, a given EBS volume can also only be attached to a single instance at once. Using this single-attachment property, we ensure that there is never any danger of multiple mounts or other potential conflicts. After the new instance starts and claims its role, clients reconnect to the targets hosted on the new instance, and no one is the wiser.
Overview
Content Tools